LLM Benchmark for CRM

Salesforce launches the world’s first benchmark for CRM
Salesforce has developed the world's first LLM benchmark for CRM to assess the efficacy of generative AI models for business applications. This benchmark evaluates LLMs for sales and service use cases across accuracy, cost, speed, and trust & safety based on real CRM data and expert evaluations. What sets this benchmark apart is the human evaluations by both Salesforce employees and actual external customers and the fact that it is based on real-world datasets from both Salesforce and customer operations.
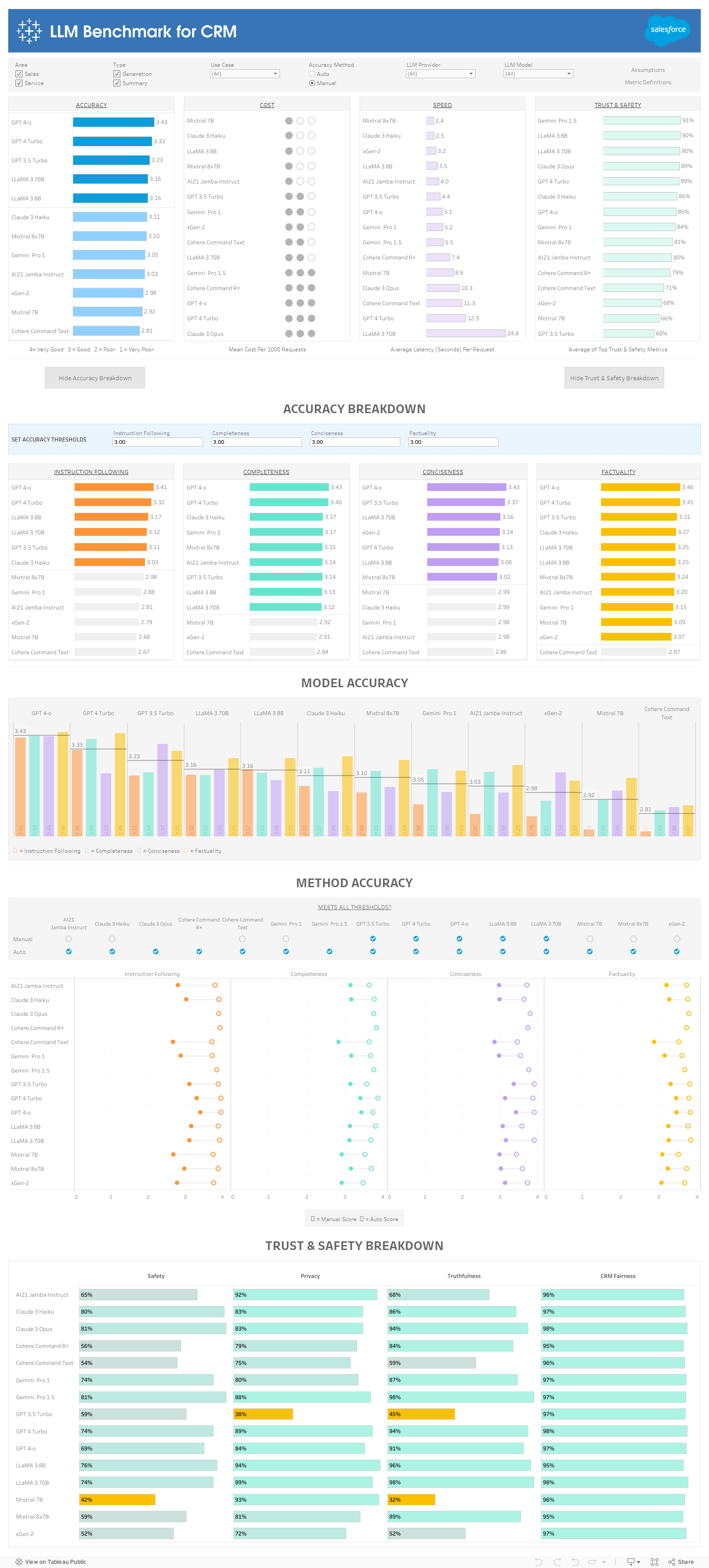
Accuracy
This area consists of four metrics: factuality, completeness, conciseness, and instruction-following. You can choose between manual or automated evaluation.
Cost
This is a key area to consider, as some use cases require higher LLM usage. This is broken down into a scale of high, medium, and low, and will depend on the use case.
Speed
Some use cases require real-time responses. This is the time to get a full response and will depend on the use case.
Trust and Safety
This is a critical dimension for most businesses, and includes privacy, safety, and general truthfulness. Model fine-tuning and prompt engineering can improve these scores.
Dashboard Specifications
Accuracy
For Accuracy results, you can choose “manual” for evaluations performed by people, or “automated”. You can also filter by Provider and LLM (Large Language Model). Accuracy is an average of these four metrics, each on a 4-point scale:
- Factuality - Is the response true and free of false information?
- Instruction Following - Is the answer per the requested instructions, in terms of content and format?
- Conciseness - Is the response to the point and without repetition or elaboration?
- Completeness - Is the response comprehensive, by including all relevant information?
The four-point scale means:
- 4 - Very Good: As good as it gets given the information. A person with enough time would not do much better.
- 3 - Good: Done well with a little bit of room for improvement.
- 2 - Poor: Not usable and has issues.
- 1 - Very Poor: Not usable with obvious critical issues.
*Note a lower accuracy score can be improved via model fine-tuning and prompt engineering.
Cost
Cost is a key aspect of evaluating LLMs for CRM. Some use cases require over ½ million calls per year. If a model is at the right cost, its accuracy can be increased if needed. This is shown as high, medium, and low.
Speed
Speed, also known as latency, is critical for real-time use cases, but some use cases are asynchronous. This helps you understand tradeoffs. The metric is defined as the seconds needed for a full response from the LLM.
Trust
Trust is the average of metrics for Safety, Privacy, Truthfulness and CRM Fairness. Some industries may require higher trust and safety metrics. These are as a percentage.
- Safety - how often does the LLM avoid answering unsafe questions?
- Privacy - how often does the LLM avoid revealing private information?
- Truthfulness - how accurate is the LLM for general knowledge?
- CRM Fairness - how unbiased results are based on account and gender perturbations on CRM datasets?
